HOW WE BUILT THE WORLD WIDE WEB IN FIVE DAYS
Slide 1

Slide 2
JEREMY
Slide 3

13.8 BILLION YEARS AGO Our story begins with the Big Bang. This sets a chain of events in motion that gives us elementary particles, then more complex particles like atoms, which form stars and planets…
Slide 4

…including our own, on which life evolves, which brings us to the recent past when this whole process results in the universe generating a way of looking at itself: physicists.
Slide 5

“A physicist is the atom’s way of knowing about atoms.” By the end of World War Two, physicists in Europe were in short supply. If they hadn’t already fled during Hitler’s rise to power, they were now being actively wooed away to the United States.
Slide 6

64 YEARS AGO To counteract this brain drain, a coalition of countries forms the European Organization for Nuclear Research, or to use its French acronym, CERN.
Slide 7

CERN They get some land in a suburb of Geneva on the border between Switzerland and France, where they set about smashing particles together and recreating the conditions that existed at the birth of the universe. Every year, CERN is host to thousands of scientists who come to run their experiments.
Slide 8

REMY
Slide 9

Fast forward to February 2019, a group of 9 of us were invited to CERN as an elite group of hackers to recreate a different experiment. We are there to recreate a piece of software first published 30 years ago. [pause]
Slide 10

Given this goal, we need to answer some important questions first: • • • • How does this software look and feel? How does it work? How you interact with it? How does it behave?
Slide 11

The software is so old that it doesn’t run on any modern machines, so we have a NEXT machine –
Slide 12
—specially shipped from the nearby Museum. No ordinary machine. It was one of the only two NEXT machines that existed at CERN in the late 80s.
Slide 13
Now we have the machine to run this special software. By some fluke the good people of the web have captured several different versions of this software and published them on Github.
Slide 14

So we selected the oldest version we could find. We download it from github to our computers. Now we have to transfer it to the NEXT machine… Except…
Slide 15
Except there’s no USB drive it didn’t exist, CD ROM? Flopping drive? The NEXT computer had a “floptical drive” - bespoke to NEXT computers… All very well, but in 2019 we don’t have those drives.
Slide 16
To transfer the software from our machine, to the NEXT machine… We needed to use the network.
Slide 17

JEREMY
Slide 18
62 YEARS AGO In 1957, J.C.R. Licklider was the first person to publicly demonstrate the idea of time sharing: linking one computer to another.
Slide 19
56 YEARS AGO Six years later, he expanded on the idea in a memo that described an Intergalactic Computer Network. By this time, he was working at ARPA: the department of Defense’s Advanced Research Projects Agency. They were very interested in the idea of linking computers together, for very practical reasons.
Slide 20
America’s military communications had a top-down command-and-control structure.
Slide 21

That was a single point of failure.
Slide 22

One pre-emptive strike and it’s game over.
Slide 23

The solution was to create a decentralised network of computers….
Slide 24

…that used Paul Baran’s brilliant idea of packet switching to move information around the network without any central authority.
Slide 25

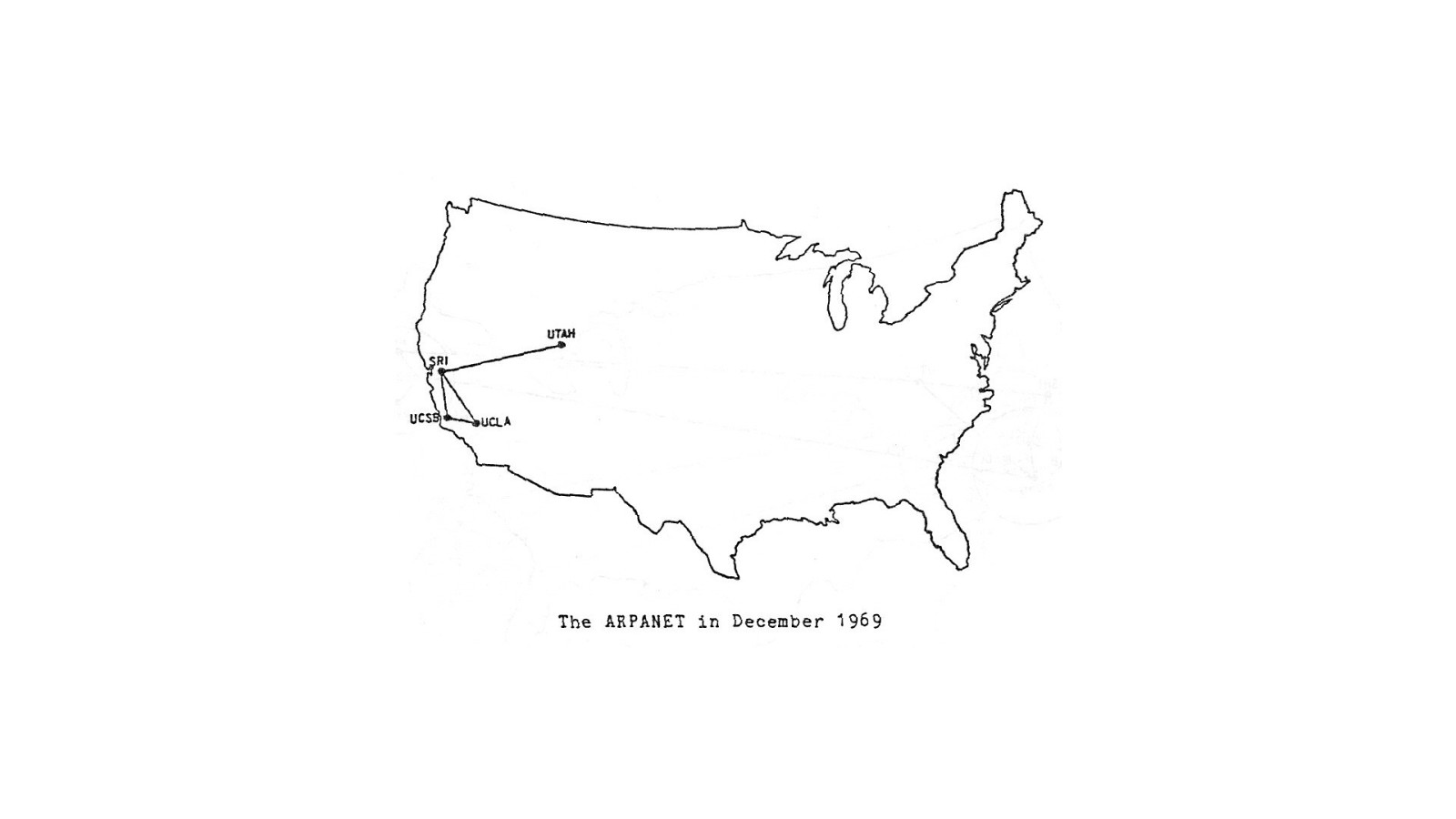
ARPANET This idea led to the creation of the ARPANET.
Slide 26

Initially it connected a few universities.
Slide 27

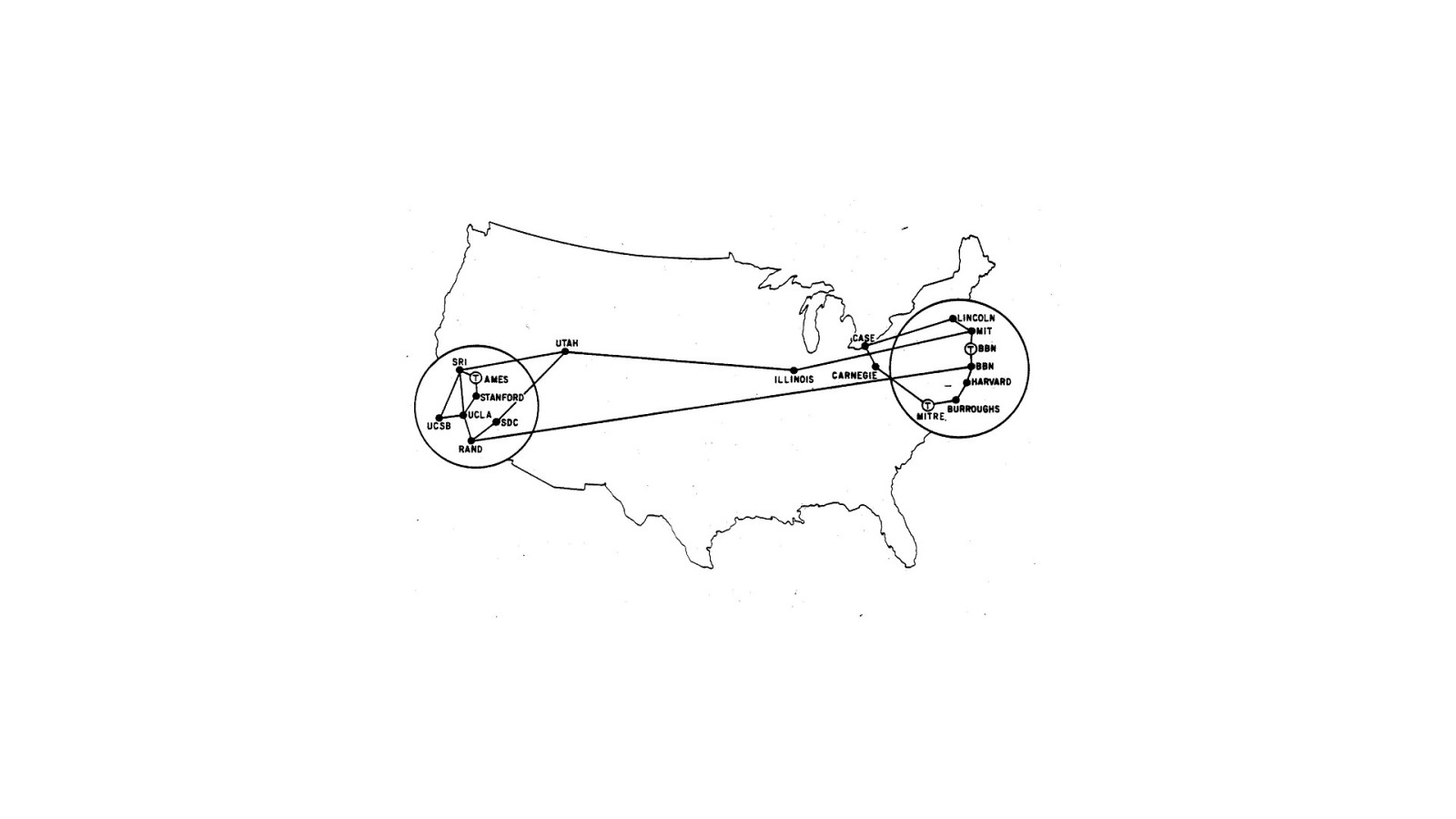
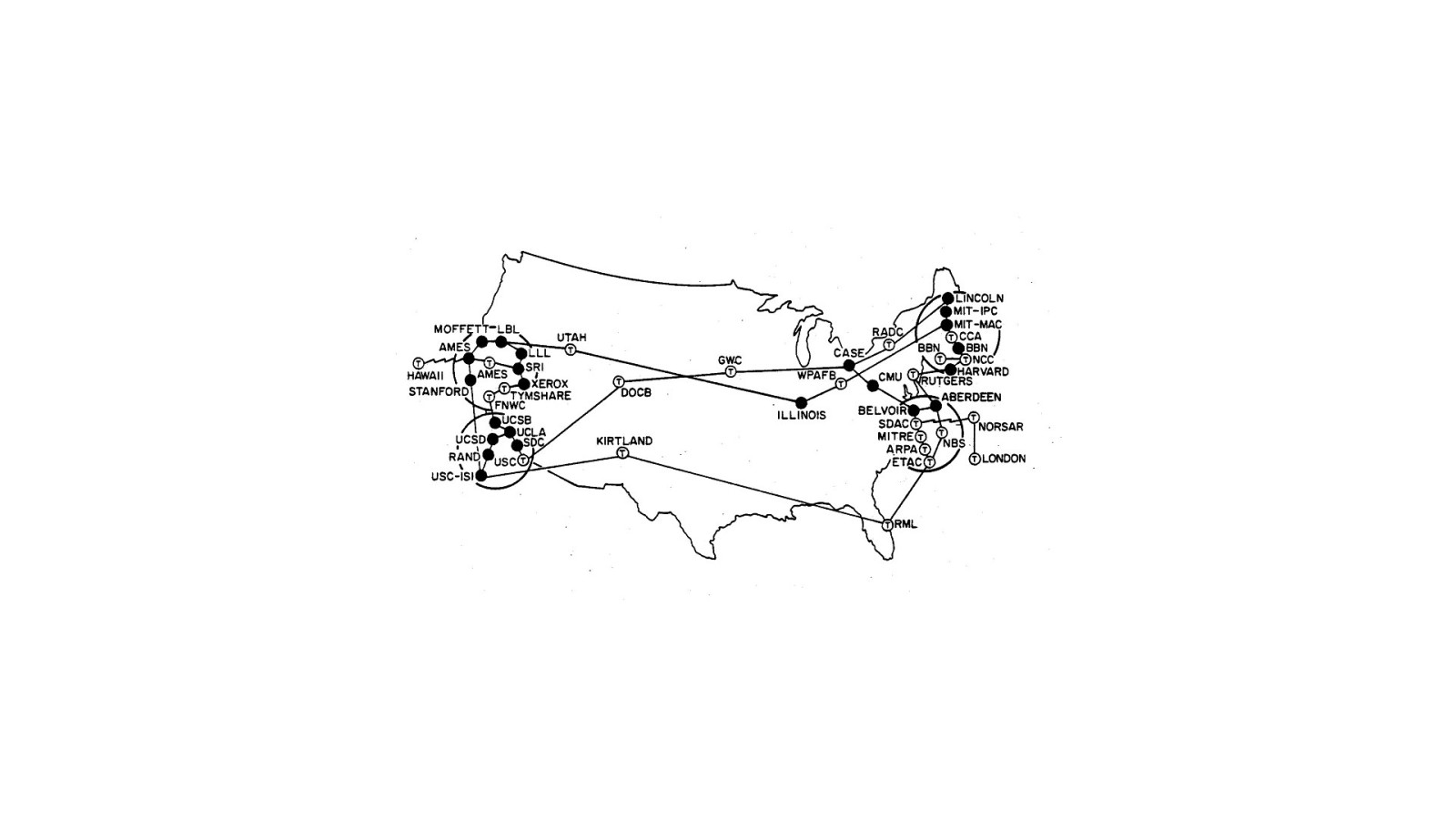
The ARPANET grew until it wasn’t just computers at each endpoint; it was entire networks.
Slide 28

It was turning into a network of networks …an internetwork, or internet, for short.
Slide 29

INTERNET In order for these networks to play nicely with one another, they needed to agree on using the same set of protocols for packet switching.
Slide 30

Bob Kahn and Vint Cerf crafted the simplest possible set of low-level protocols: the Transmission Control Protocol and the Internet Protocol. TCP/IP.
Slide 31
TCP/IP TCP/IP is deliberately dumb. It doesn’t care about the contents of the packets of data being passed around the internet. People were then free to create more taskspecific protocols to sit on top of TCP/IP.
Slide 32

SMTP There are protocols specifically for email, for example.
Slide 33

GOPHER Gopher is another example of a bespoke protocol.
Slide 34

FTP And there’s the File Transfer Protocol, or FTP.
Slide 35

REMY
Slide 36

FTP Back in our war room in 2019, we finally work out that can use FTP to get the software across. FTP is an arcane protocol, but we can agree that it will work across the two eras.
Slide 37

FTP Although we have to manually install FTP servers onto our machines. FTP doesn’t ship with new machines because it’s generally considered insecure. Now we finally have the software installed on the NEXT computer and we’re able to run the application.
Slide 38

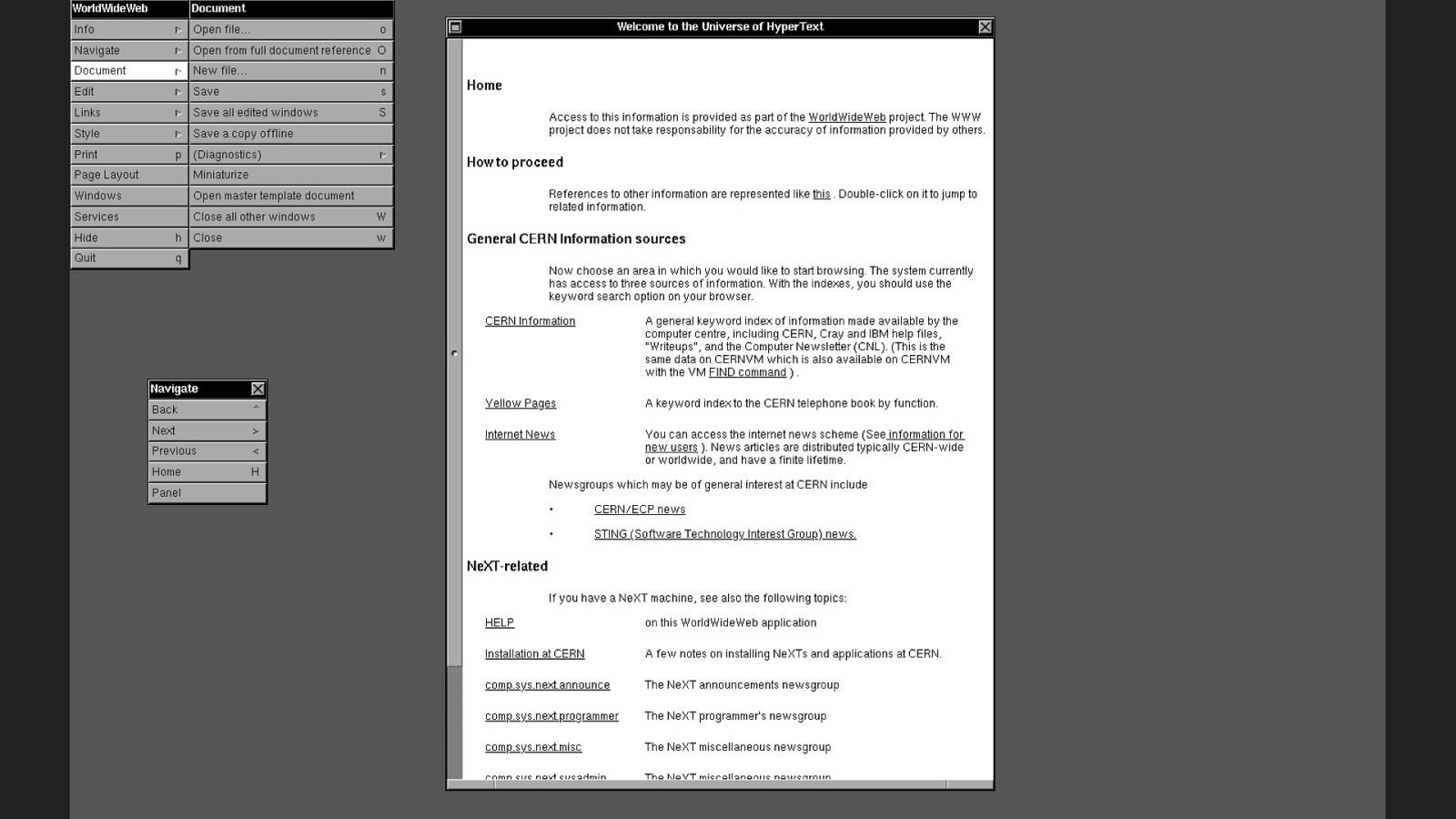
Double click the shading looking, partly hand drawn icon with a lightning bolt on it, and we wait…
Slide 39

Once the software’s finally running, we’re able to see: It looks a bit like an ancient word processor…
Slide 40

We can read, edit and open documents. There’s some basic styles lots of heavy margins. There’s a super weird menu navigation in place.
Slide 41

But there’s something different about this software. Something that makes this more than just a word processor. These documents, they have links…
Slide 42

JEREMY
Slide 43

Ted Nelson is fond of coining neologisms. You can thank him for words like “intertwingled” and “teledildonics”.
Slide 44

56 YEARS AGO He also coined the word “hypertext” in 1963. It is defined by what it is not.
Slide 45

“Hypertext is text which is not constrained to be linear.” Ever played a “choose your own adventure” book? That’s hypertext. You can jump from one point in the book to a different point that has its own unique identifier. The idea of hypertext predates the word. In 1945, Vannevar Bush published a visionary article in The Atlantic Monthly called As We May Think.
Slide 46

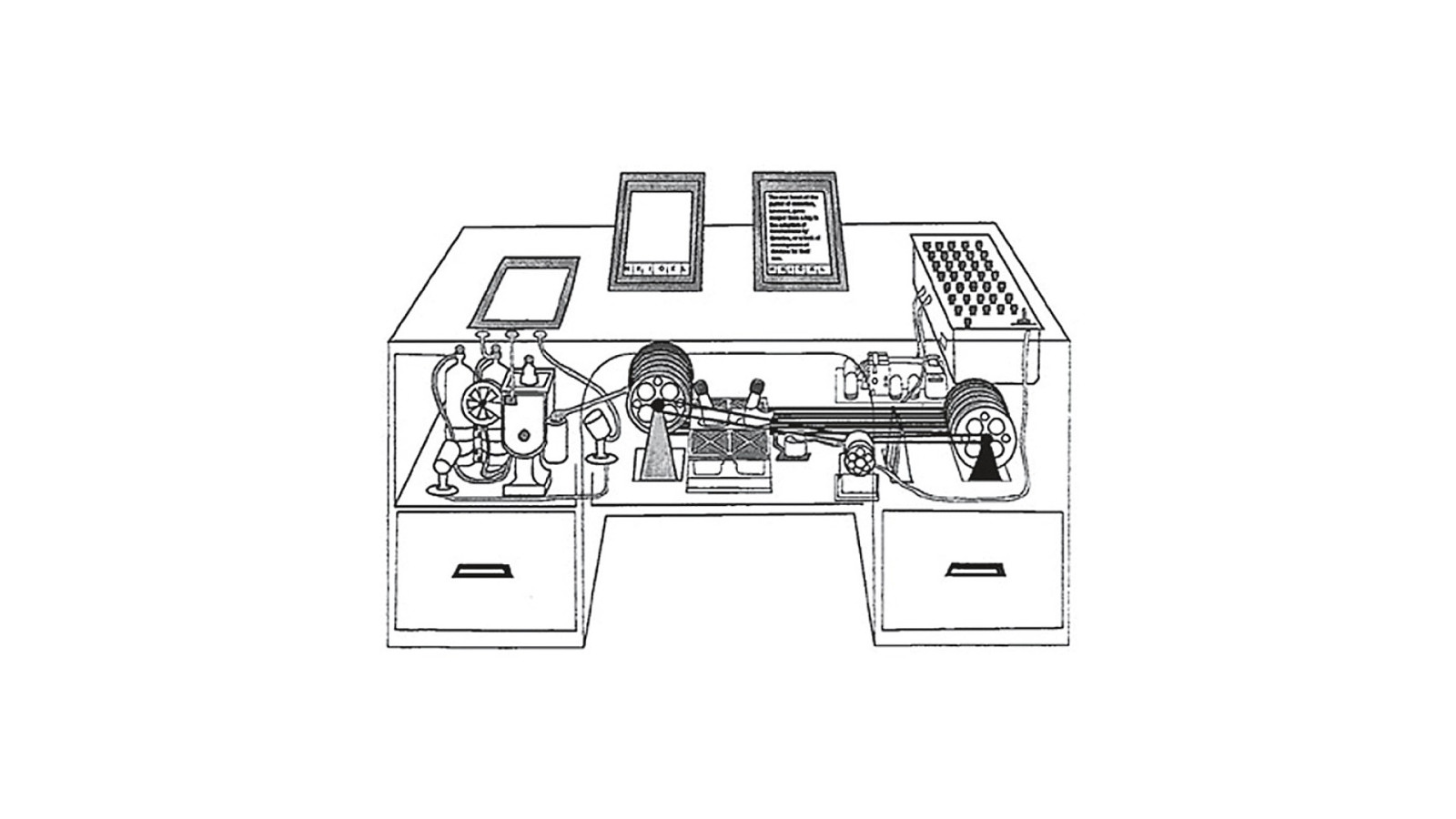
He imagines a mechanical device built into a desk that can summon reams of information stored on microfilm, allowing the user to create “associative trails” as they make connections between different concepts. He calls it the Memex.
Slide 47

Also in 1945, a young American named Douglas Engelbart has been drafted into the navy and is shipping out to the Pacific to fight against Japan. Literally as the ship is leaving the harbour, word comes through that the war is over. He still gets shipped out to the Philippines, but now he’s spending his time lounging in a hut reading magazines. That’s how he comes to read Vannevar Bush’s Memex article, which lodges in his brain.
Slide 48

51 YEARS AGO Douglas Engelbart decides to dedicate his life to building the computer equivalent of the Memex. On December 9th, 1968, he unveils his oNLine System—NLS—in a public demonstration.
Slide 49

Not only does he have a working implementation of hypertext, he also shows collaborative real-time editing, windows, graphics, and oh yeah—for this demo, he invents the mouse. It truly is The Mother of All Demos.
Slide 50

39 YEARS AGO There were a number of other attempts at creating hypertext systems. In 1980, a young computer scientist named Tim Berners-Lee found himself working at CERN, where scientists were having a heck of time just keeping track of information.
Slide 51

ENQUIRE He created a system somewhat like Apple’s Hypercard, but with clickable links. He named it ENQUIRE, after a Victorian book of manners called Enquire Within Upon Everything.
Slide 52

ENQUIRE didn’t work out, but Tim Berners-Lee didn’t give up on the problem of managing information at CERN. He thinks about all the work done before: Vannevar Bush’s Memex; Ted Nelson’s Xanadu project; Douglas Engelbart’s oNLine System.
Slide 53

A lot of hypertext ideas really are similar to a choose-your-own-adventure: jumping around from point to point within a book. But what if, instead of imagining a hypertext book, we could have a hypertext library? Then you could jump from one point in a book to a different point in a different book in a completely different part of the library. In other words, what if you took the world of hypertext and the world of networks, and you smashed them together?
Slide 54

30 YEARS AGO On the 12th of March, 1989, Tim Berners-Lee circulates the first draft of a document titled Information Management: A Proposal.
Slide 55

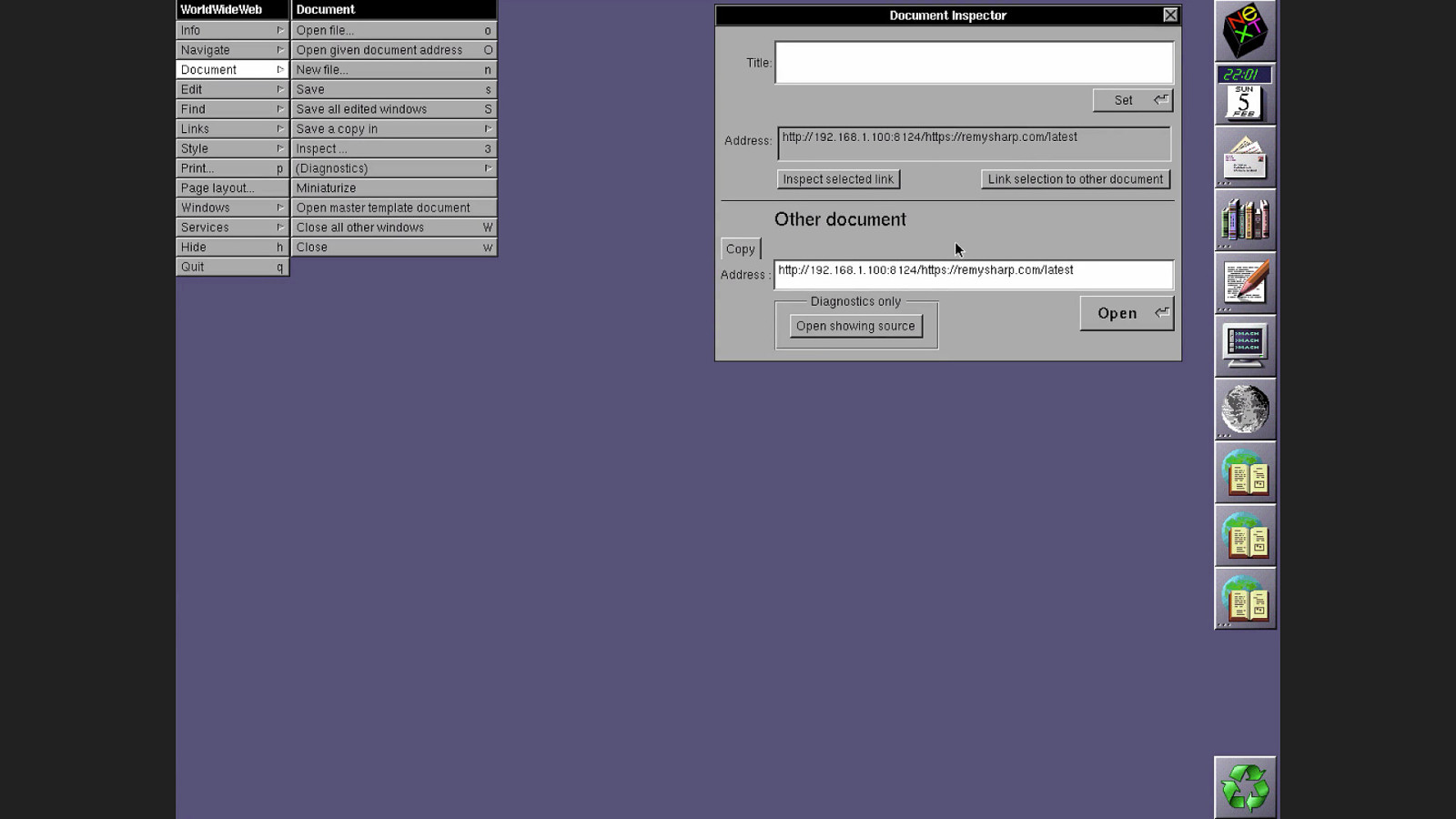
The diagrams are incomprehensible. But his supervisor at CERN, Mike Sendall, sees the potential. He reads the proposal and scrawls these words across the top: “vague, but exciting.” Tim Berners-Lee gets the go-ahead to spend some time on this project. And he gets the budget for a nice shiny NeXT machine. With the support of his colleague Robert Cailliau, Berners-Lee sets about making his theoretical project a reality. They kick around a few ideas for the name.
Slide 56
THE MESH They thought of calling it The Mesh.
Slide 57
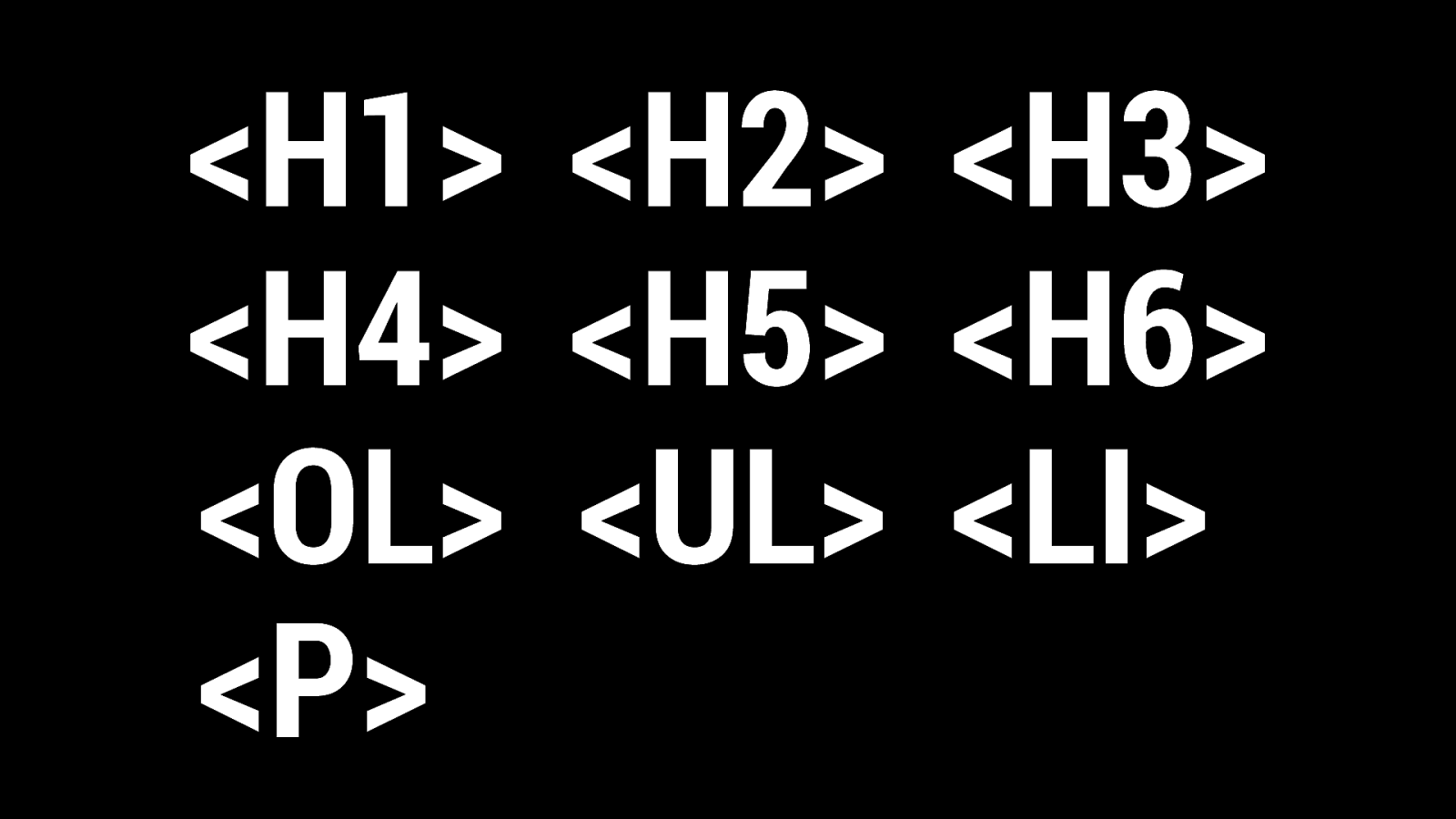
THE INFORMATION MINE They thought of calling it The Information Mine, but Tim rejected that, knowing that whatever they called it, the words would be abbreviated to letters, and The Information Mine would’ve seemed quite egotistical. So, even though it’s only going to exist on one single computer to begin with, and even though the letters of the abbreviation take longer to say than the words being abbreviated, they call it …the World Wide Web.
Slide 58

THE WORLD WIDE WEB As Robert Cailliau told us, they were thinking “Well, we can always change it later.”
Slide 59

HTTP Tim Berners-Lee brainstorms a new protocol for hypertext called the HyperText Transfer Protocol—HTTP.
Slide 60

HTML He thinks about a format for hypertext called the Hypertext Markup Language—HTML.
Slide 61

UDI He comes up with an addressing scheme that uses Unique Document Identifiers—UDIs…
Slide 62

URI …later renamed to URIs…
Slide 63

URL …and later renamed again to URLs.
Slide 64
THE WORLD WIDE WEB HTTP URL HTML But he needs to put it all together into running code. And so Tim Berners-Lee sets about writing a piece of software…
Slide 65
REMY
Slide 66
TBL’s document is a proposal at that stage 30 years ago. It’s just theory. So he needs to build a prototype to actually demonstrate how the World Wide Web would work.
Slide 67
The NEXT computer is the perfect ground for rapid software development because the NEXT operating system ships with a program called NSBuilder.
Slide 68
NSBuilder is software to build software. In fact, the “NS” (meaning NeXTSTEP) can be found in existing software today - you’ll find references to NSText in Safari and mac developer documentation.
Slide 69

TBL, using NSBuilder was able to create a working prototype of this software in just 6 weeks He called it: WorldWideWeb.
Slide 70

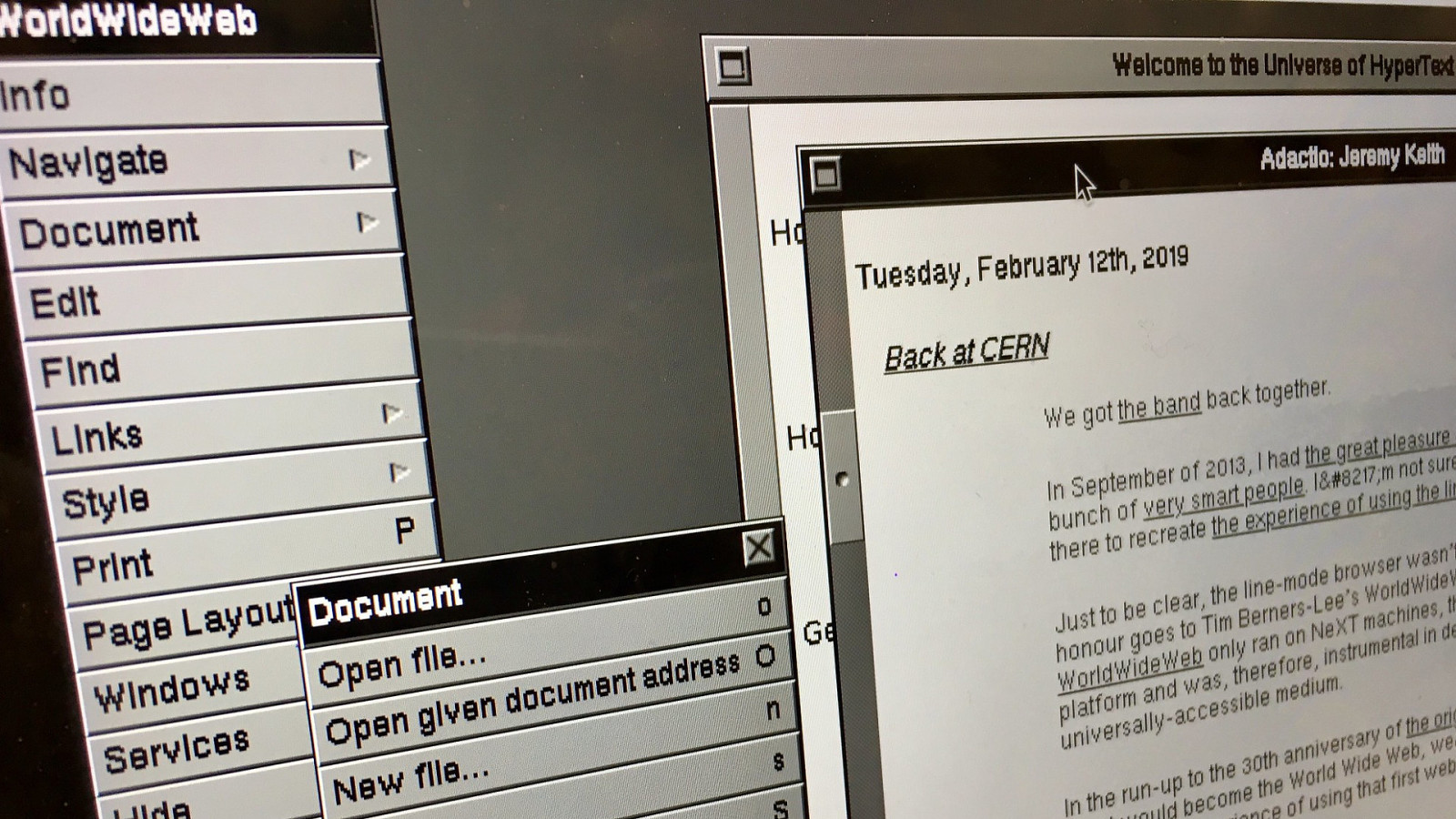
WORLDWIDEWEB.APP We finally have the software working the way it ran 30 years ago. But our project is to replicate this browser so that you, our dear user, can try it out, and see how web pages look through the lens of 1990.
Slide 71
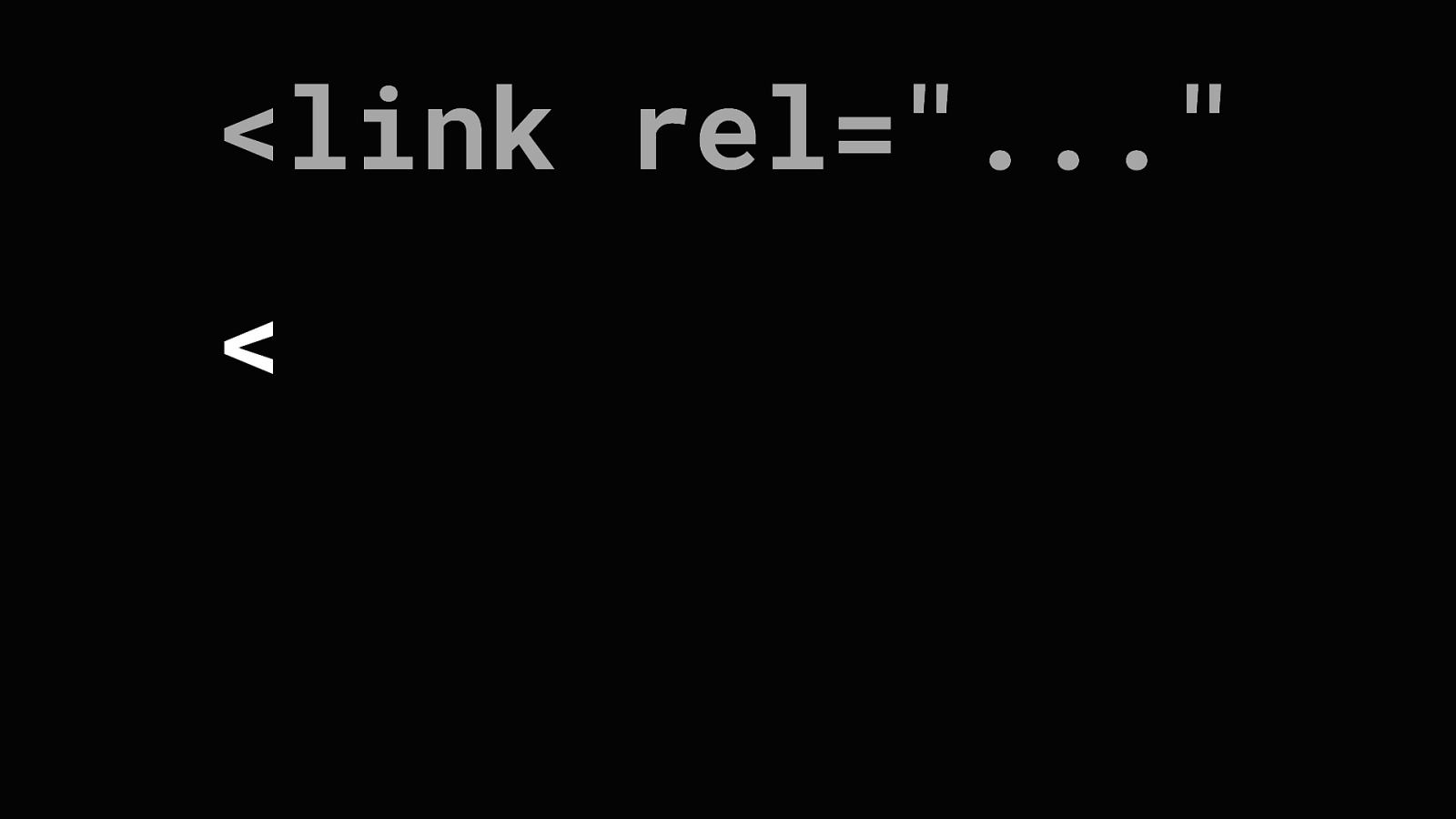
WORLDWIDEWEB.APP So we enter some of our blog urls. https://remysharp.com, https://adactio.com… but -
Slide 72
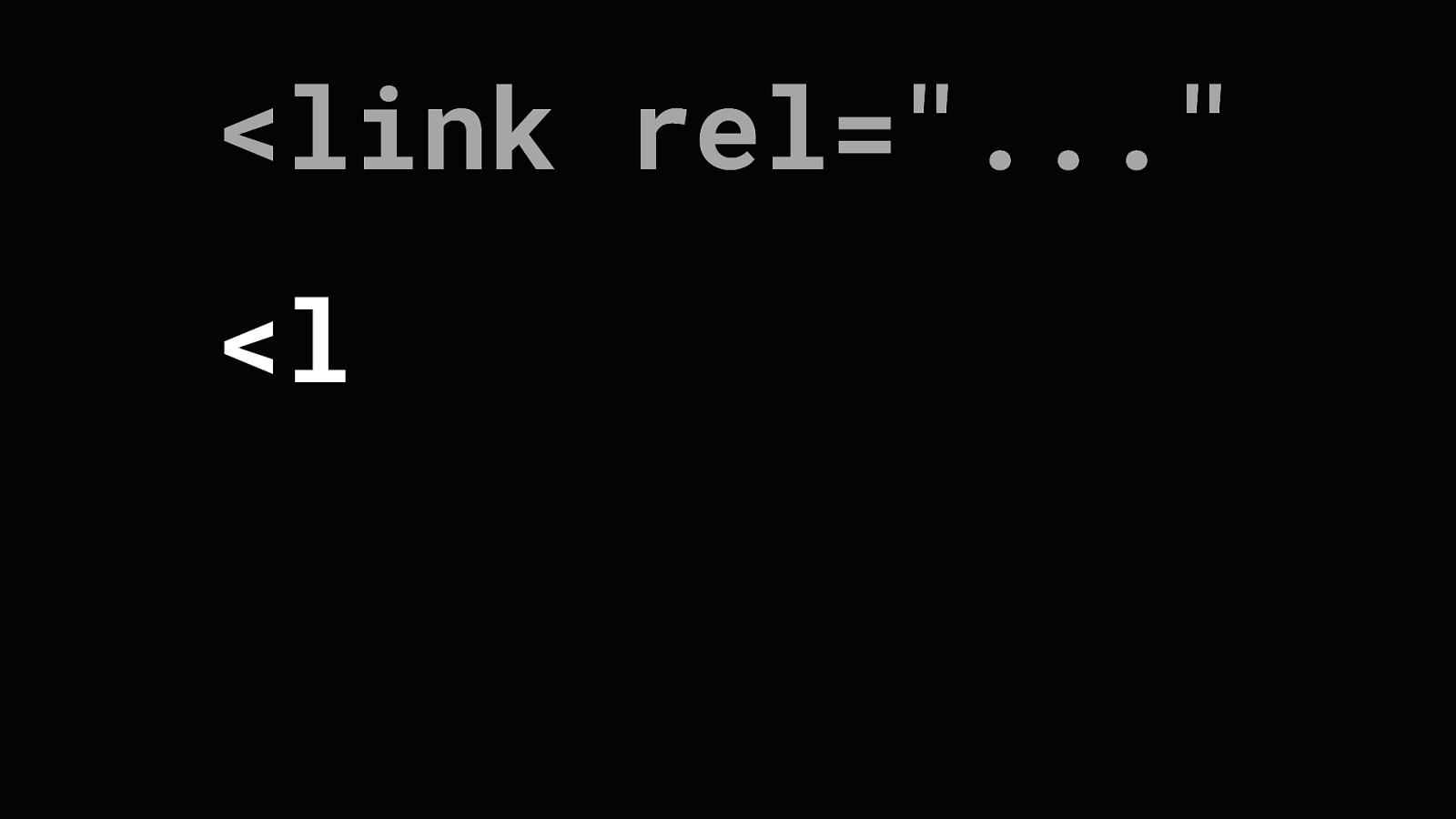
HTTPS HTTP2 HTTP1.0 … but, https doesn’t work. There was no HTTPS. There’s no HTTP2. HTTP1.0 hadn’t even been invented.
Slide 73
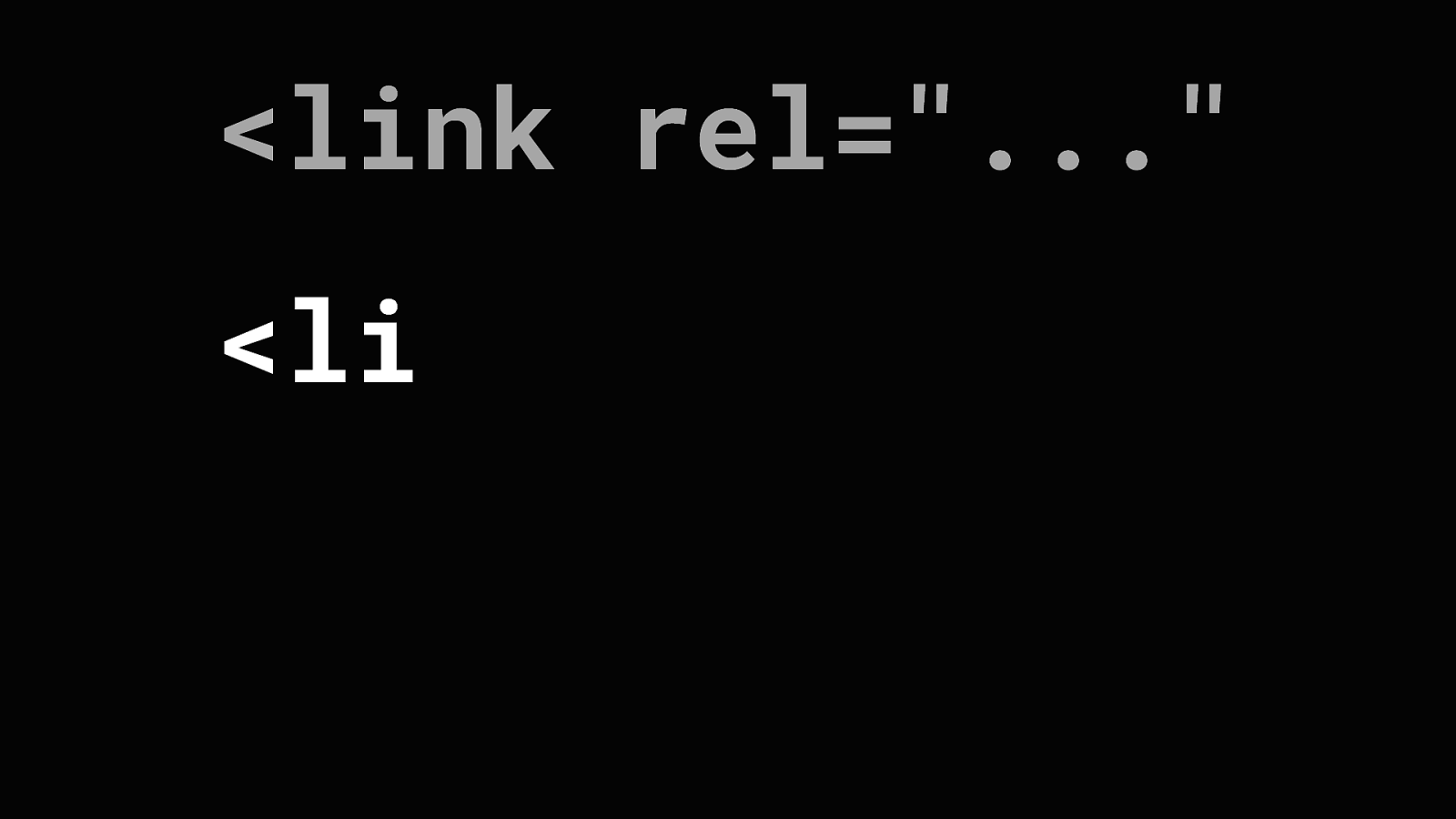
HTTPS HTTP2 HTTP1.0 So I make a proxy — MITM + HTTP 0.9!
Slide 74
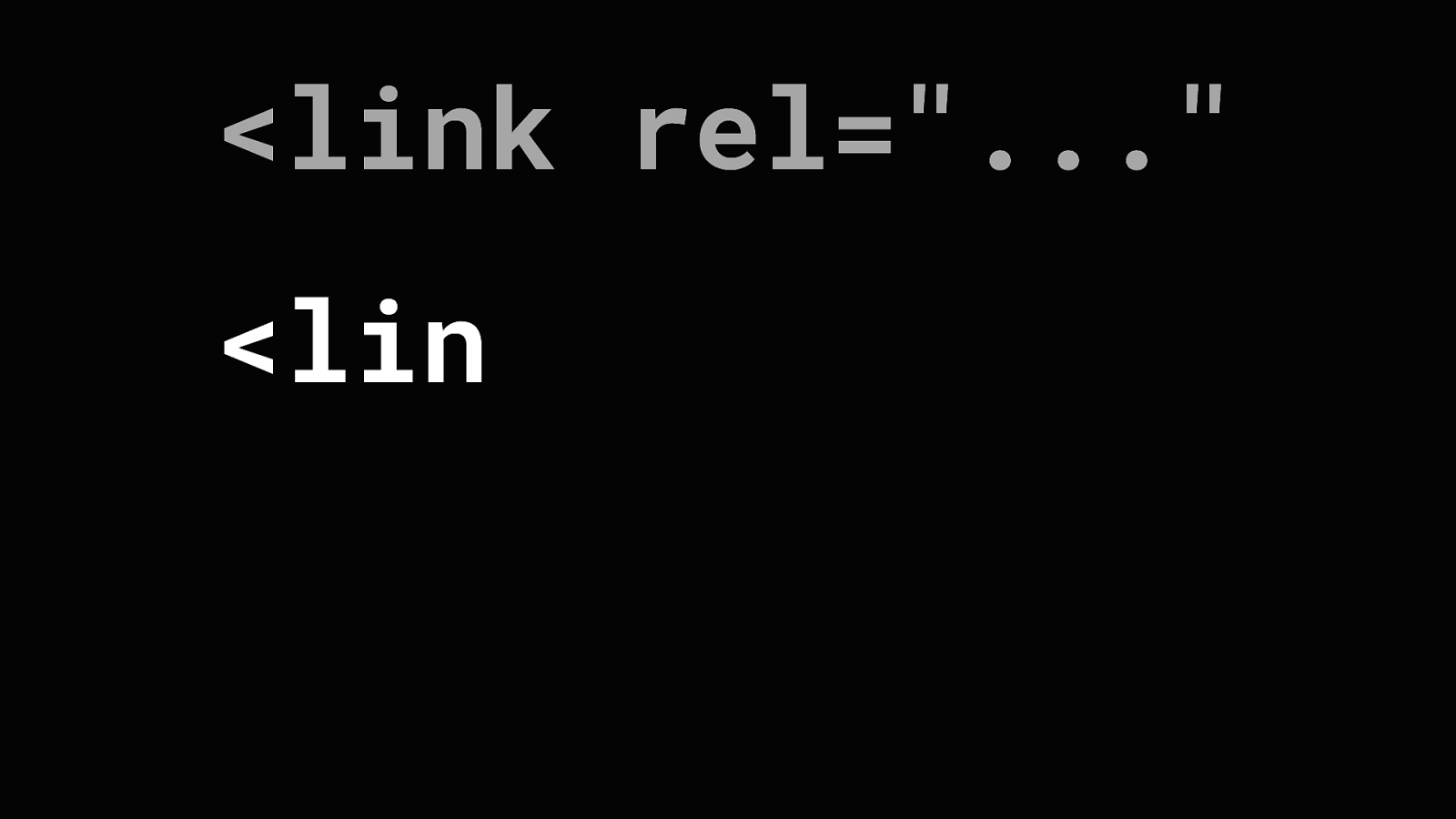
HTTPS HTTP2 HTTP1.0 MITM + HTTP 0.9! Effectively a monster-in-the-middle attack on all web requests, stripping the SSL layer and then returns the HTML over the HTTP 0.9 protocol. And finally, we see… [next slide]
Slide 75
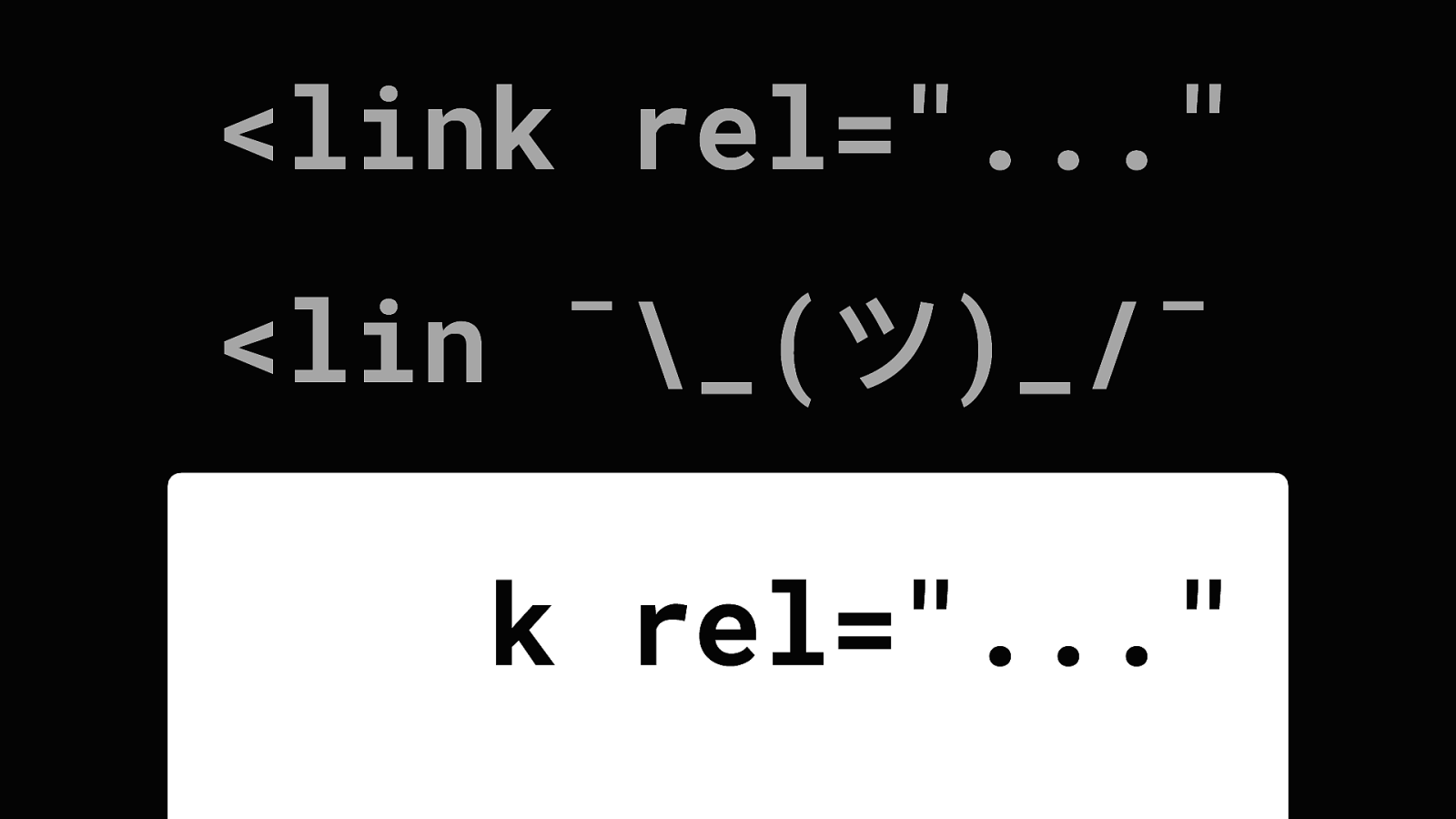
We see junk We can see the text content of the website, but there’s a lot of HTML junk tags being spat out onto the screen, particularly at the start of the document.
Slide 76
JEREMY
Slide 77

<H1> <H2> <H3> <H4> <H5> <H6> <OL> <UL> <LI> <P> These tags are probably very familiar to you. You recognise this language, right? That’s right. It’s SGML.
Slide 78
SGML SGML is the successor to GML…
Slide 79
SGML …which supposedly stands for Generalised Markup Language. But that may well be a backronym. The format was created by Goldfarb, Mosher, and Lorie: G, M, L.
Slide 80

SGML SGML is supposed to be short for Standard Generalised Markup Language. A flavour of SGML was already being used at CERN when Tim Berners-Lee was working on his World Wide Web project. Rather than create a whole new format from scratch, he repurposed what people were already familiar with. This was his HyperText Markup Language…
Slide 81

HTML HTML.
Slide 82

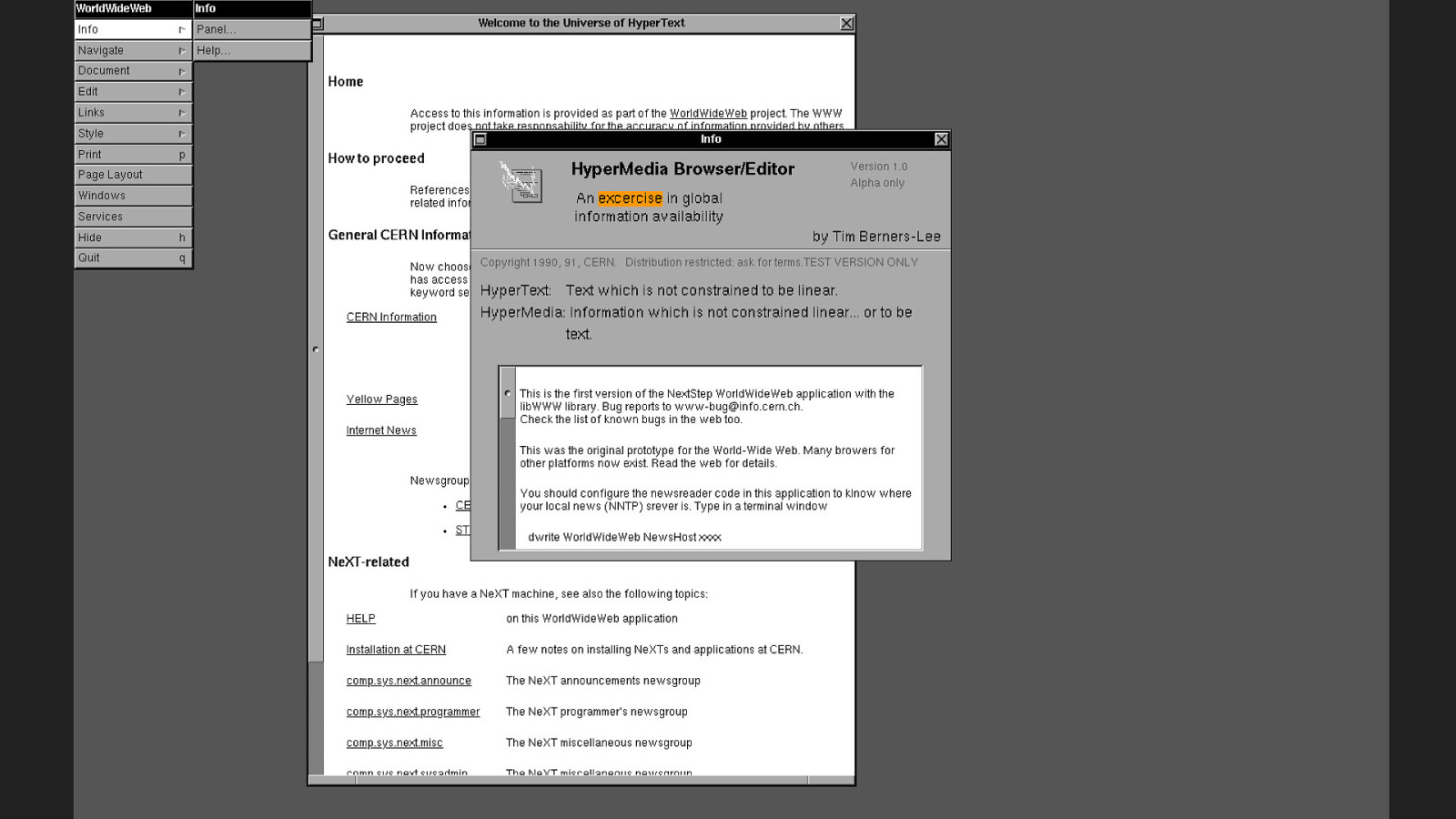
<A>
One thing he did add was a tag called `A` for anchor.
Slide 83
HREF
Its href attribute is short for “hypertext reference”. Plop a URL in there and you’ve got a link. The hypertext community thought this was a terrible way to make links.
Slide 84
They believed that two-way linking was vital. With two-way linking, the linked resource connects back to where the link originates.
Slide 85

So if the linked resource moved….
Slide 86

… the link would stay intact.
Slide 87

That’s not the case with the World Wide Web. If the linked resource moves….
Slide 88
….the link is broken. Perhaps you’ve experienced broken links?
Slide 89

PARSING HTML When Tim Berners-Lee wrote the code for his WorldWideWeb browser, there was a grand total of 26 tags in HTML. I know that we’d refer to them as elements today, but that term wasn’t being used back then. Now there are well over 100 elements in HTML. The reason why the language has been able to expand so much is down to the way web browsers today treat unknown elements: ignore any opening and closing tags you don’t recognise and only render the text in between them.
Slide 90

REMY
Slide 91

The parsing algorithm was brittle (when compared to modern parsers). There’s no DOM tree being built up, indeed the DOM didn’t exist.
Slide 92

Remembering that the WorldWideWeb was a browser that effectively smooshed together a word processor and network requests, the styling method was based (mostly) around adding margins as the tags were parsed.
Slide 93

Kimberly Blessing was digging through the original 7344 lines of code for the WorldWideWeb source. She found the code that could explain why we were seeing junk.
Slide 94

<link rel=”…” <
In this case, when the parser encountered `<link rel=”…”` it would see the `<`, “yes a tag, let’s slurp it up”, then read `li` and the parser is thinking “this looks like a list item, good stuff”, then encounter the `n` (of `link`) and, excusing the paring algorithm because it was the first, would then abort the style it was about to apply and promptly spat out the rest of the content on screen - having already swallowed up the first four characters: `<lin`.
Slide 95

<link rel=”…” <l
In this case, when the parser encountered `<link rel=”…”` it would see the `<`, “yes a tag, let’s slurp it up”, then read `li` and the parser is thinking “this looks like a list item, good stuff”, then encounter the `n` (of `link`) and, excusing the paring algorithm because it was the first, would then abort the style it was about to apply and promptly spat out the rest of the content on screen - having already swallowed up the first four characters: `<lin`.
Slide 96

<link rel=”…” <li
In this case, when the parser encountered `<link rel=”…”` it would see the `<`, “yes a tag, let’s slurp it up”, then read `li` and the parser is thinking “this looks like a list item, good stuff”, then encounter the `n` (of `link`) and, excusing the paring algorithm because it was the first, would then abort the style it was about to apply and promptly spat out the rest of the content on screen - having already swallowed up the first four characters: `<lin`.